Attention
Attention 은 입력 시퀀스의 각 요소(토큰)가 다른 모든 요소와의 관계(연관성, 유사도)를 동적으로 계산하여, 중요한 정보에 더 집중할 수 있도록 하는 방법이다. 즉, 입력 전체를 한 번에 바라보면서, 각 토큰이 다른 토큰들과 얼마나 관련이 있는지 가중치를 부여해 정보를 집계한다.
1. 기본 아이디어
기존 RNN 기반 모델은 입력을 순차적으로 처리하기 때문에, 먼 거리의 토큰 간 관계를 학습하는 데 한계가 있었다. Attention은 입력 시퀀스 전체를 동시에 바라보고, 각 토큰이 다른 토큰들과 얼마나 중요한지(얼마나 "집중"해야 하는지)를 계산한다.
2. Self-Attention (자기-어텐션)
Transformer에서 가장 핵심적인 형태의 Attention이다.
- Self-Attention은 입력 시퀀스 내의 각 토큰이, 같은 시퀀스 내의 다른 모든 토큰과의 관계를 계산한다.
- 예를 들어, "나는 학교에 갔다"라는 문장에서 "나는"이 "갔다"와 얼마나 관련이 있는지, "학교"와는 얼마나 관련이 있는지 등을 동적으로 계산한다.
3. 계산 과정
Self-Attention의 계산은 다음과 같이 이루어진다.
-
Query, Key, Value 생성
- 각 입력 토큰 임베딩에서 세 가지 벡터(Query, Key, Value)를 생성한다.
, , (여기서 는 입력 임베딩, 는 학습 가능한 가중치 행렬)
-
유사도(Attention Score) 계산
- Query와 Key의 내적(dot product)을 통해 각 토큰 쌍의 유사도를 계산한다.
-
정규화(Softmax)
- 각 토큰에 대해, 모든 토큰과의 유사도를 Softmax로 정규화하여 가중치(Attention Weight)를 만든다.
-
가중합
- 각 토큰의 Value 벡터에 위에서 구한 가중치를 곱해, 최종적으로 새로운 표현을 만든다.
-
스케일링
- 안정적인 학습을 위해, 유사도 계산 시
로 나누어준다. ( 는 Key 벡터의 차원)
- 안정적인 학습을 위해, 유사도 계산 시
4. Multi-Head Attention
- Self-Attention을 여러 번(Head) 병렬로 수행한다.
- 각 Head는 서로 다른 가중치로 Query, Key, Value를 생성해 다양한 관점에서 정보를 추출한다.
- 여러 Head의 출력을 합쳐 최종 Attention 출력을 만든다.
5. Encoder-Decoder Attention
- Transformer의 Decoder에서는 Encoder의 출력(입력 시퀀스 정보)과 Decoder의 출력(생성 중인 시퀀스 정보)을 결합하는 Attention을 사용한다.
- 이를 통해 Decoder가 입력 시퀀스의 특정 부분에 집중할 수 있다.
6. Masked Attention
- Decoder에서는 미래 토큰을 보지 못하도록 마스킹(Masking)된 Attention을 사용한다.
- 예측 시점 이전의 정보만 참고할 수 있도록 한다.
7. 수식 요약
Self-Attention의 전체 수식은 다음과 같다.
8. 장점
- 병렬 연산: 입력 전체를 한 번에 처리할 수 있다.
- 장기 의존성: 먼 거리의 토큰 관계도 잘 학습한다.
- 유연성: 다양한 입력 길이와 구조에 적용 가능하다.
9. 시각적 예시
아래 그림은 Self-Attention의 동작 방식을 시각적으로 보여준다.
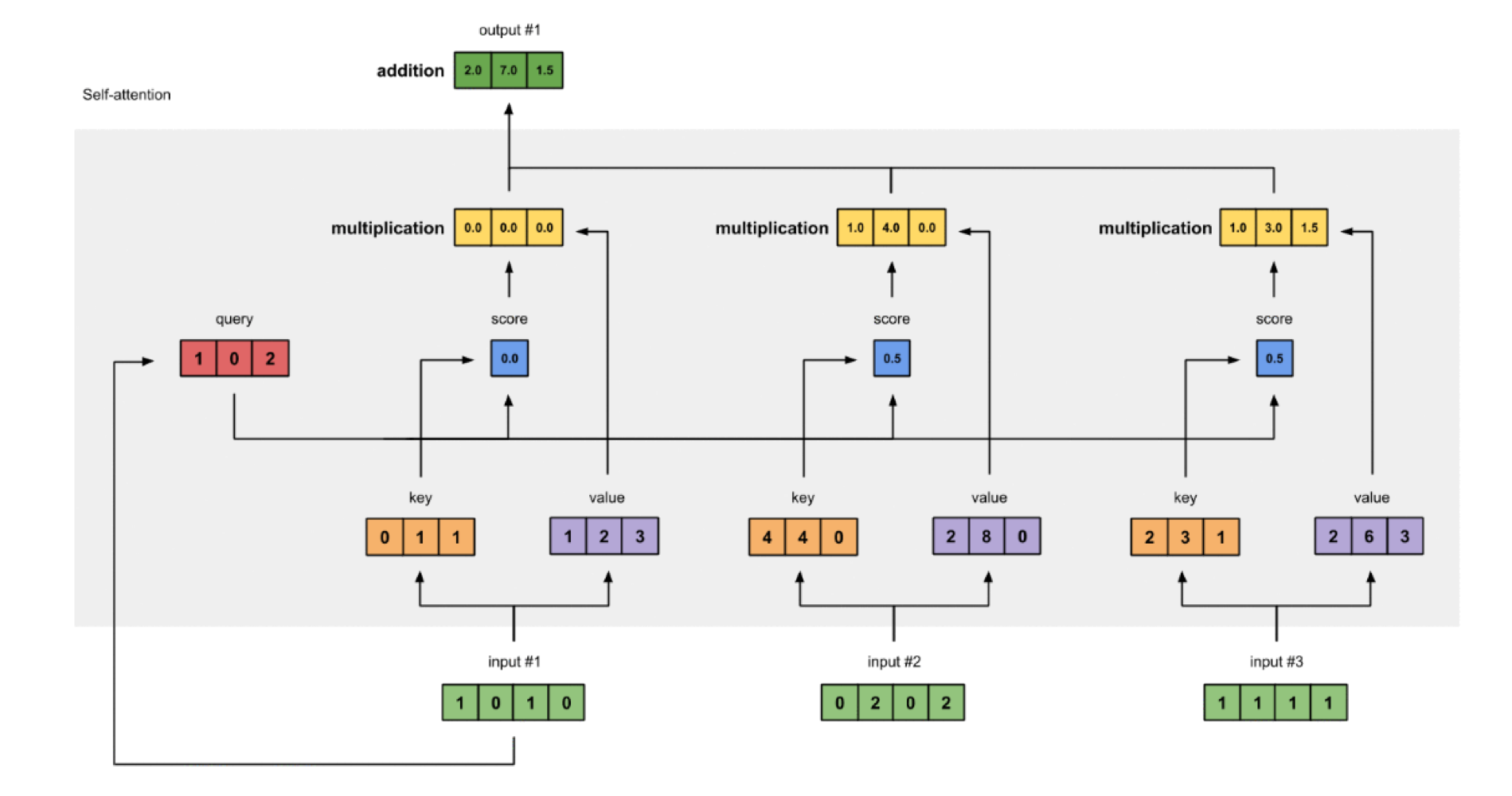
- 각 입력 토큰(예: "나는", "학교에", "갔다")이 다른 모든 토큰과의 관계를 계산한다.
- 각 토큰별로 Query, Key, Value를 만들고, 유사도를 계산해 가중치를 얻는다.
- 이 가중치로 Value들을 가중합하여, 각 토큰의 새로운 표현을 만든다.
- 여러 Head에서 이 과정을 병렬로 수행한 뒤, 결과를 합쳐 최종 출력을 만든다.
10. Attention의 종류
Transformer에서는 다음과 같은 Attention이 사용된다.
| 종류 | 설명 |
|---|---|
| Self-Attention | 입력 시퀀스 내에서 각 토큰이 서로를 참고(Encoder, Decoder 모두 사용) |
| Masked Self-Attention | 미래 토큰을 마스킹(Decoder에서 사용) |
| Encoder-Decoder Attention | Encoder 출력과 Decoder 출력을 결합(Decoder에서 사용) |
11. Attention의 역할
- 정보 집약: 각 토큰이 다른 토큰에서 중요한 정보를 동적으로 받아온다.
- 의존성 학습: 문장 내에서 멀리 떨어진 단어들 간의 관계도 잘 포착한다.
- 병렬 처리: 모든 토큰 쌍의 관계를 동시에 계산할 수 있어, RNN 대비 학습 속도가 빠르다.
12. 한계 및 개선
- 계산량 증가: 입력 시퀀스 길이가 길어질수록 연산량이
로 증가한다. - 순서 정보: Attention 자체에는 순서 정보가 없으므로, Positional Encoding을 추가로 사용한다.
- 효율화 연구: Longformer, Performer 등 다양한 효율화 모델이 등장하고 있다.
13. 요약
- Attention 메커니즘은 입력 시퀀스 내에서 각 토큰이 다른 토큰과의 관계를 동적으로 계산해, 중요한 정보에 집중할 수 있게 한다.
- Transformer의 핵심 구성 요소로, Self-Attention, Multi-Head Attention, Encoder-Decoder Attention 등 다양한 형태로 활용된다.
- 병렬 연산, 장기 의존성 학습 등 여러 장점을 가지며, 자연어 처리뿐 아니라 다양한 분야에서 널리 사용되고 있다.